Las empresas de EEUU siguen empeñadas en modelos IA más y más grandes. Las de China siguen demostrando que no hace falta
Alibaba tenía hasta ahora un modelo abierto estupendo para programar. Se traba de Qwen3.5-397B-A17B, pero el problema es que era gigantesco con sus 397.000 millones de parámetros y sus 807 GB de tamaño en disco (y memoria). La empresa china ha hecho algo sorprendente y ha anunciado estos días el mod

Image: Xataka
Alibaba tenía hasta ahora un modelo abierto estupendo para programar. Se traba de Qwen3.5-397B-A17B, pero el problema es que era gigantesco con sus 397.000 millones de parámetros y sus 807 GB de tamaño en disco (y memoria). La empresa china ha hecho algo sorprendente y ha anunciado estos días el modelo Qwen3.6-27B, que en su versión cuantizada pesa menos de 17 GB. Cualquiera pensaría que con ese tamaño sería mucho peor que su hermano mayor. Pero se equivocaría. Es la prueba de que es posible dar por mucho menos.
Un modelo denso. La mayoría de modelos grandes de pesos abiertos en 2026 usan arquitectura Mixture-of-Experts (MoE): tienen muchos parámetros en total, pero solo activan una fracción de ellos cuando los usamos. Por ejemplo el modelo Qwen3.5-397B-A17B precisamente indicaba eso en su nombre: de los 397.000 millones de parámetros, tan solo activaba 17.000 millones (de ahí el A17B) al usarlo.
Con Qwen3.6-27B tenemos lo que se llama un modelo denso: los 27.000 millones de parámetros se activan en cada inferencia. Aunque es algo menos eficiente, tienen ventajas prácticas claras. Por ejemplo, no es necesario configurar un enrutador de expertos, y la cuantización es más predecible y compacta. La idea ha funcionado, y los resultados lo demuestran.
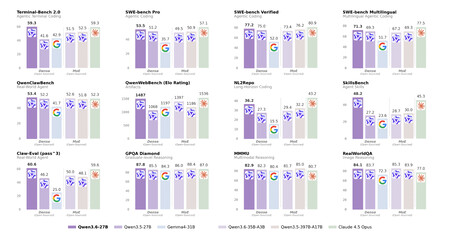 El rendimiento de este "pequeño" modelo de IA es incluso superior a una versión anterior mucho más grande.
El rendimiento de este "pequeño" modelo de IA es incluso superior a una versión anterior mucho más grande.
Los benchmarks no mienten (demasiado). En SWE-bench Verified, el benchmark más popular para tareas de programación real, Qwen3.6-27B logra el 77,2% de puntuación frente al 76,2% del modelo de 397B. En Terminal-Bench 2.0, que mide qué tal ejecuta el modelo tareas en la consola de comandos, logró un 59,3% frente al 2,5% de su rival. Pero es que en esta prueba logra exactamente la misma puntuación que Claude Opus 4.5, uno de los mejores modelos recientes de Anthropic. Que un modelo "Open Source" que se puede usar en local con facilidad logre algo así es insólito, pero debemos ser cautos: los benchmarks son de la propia Alibaba, y no hay de momento verificación independiente aunque quienes lo están usando parecen estar realmente satisfechos con él.
Hasta Alibaba se sorprende. Lo que es llamativo de este lanzamiento es que la propia empresa que lo ha lanzando está impulsándolo por encima de su modelo más ambicioso hasta hace poco. Que ellos mismos comparen ambas versiones y reconozcan que el "pequeño" es el más potente es significativo. Es como decir a los cuatro vientos que los modelos de IA más grandes no tienen competencia, cuando ellos acaban de comprobar que no es así y que modelos como Qwen3.6-27B pueden ser realmene notables en comportamiento.
Artículo original
Las empresas de EEUU siguen empeñadas en modelos IA más y más grandes. Las de China siguen demostrando que no hace falta
Publicado por Xataka