Kimi Code hace el 75% de lo que hace Claude Code al 20% de su precio. La pregunta es si ese 25% que falta es el que importa
Hace unos días, la empresa china Moonshot AI lanzaba Kimi K2.6, su nuevo LLM que compite con las familias de modelos de Gemini, GPT y Claude y que además es especialmente competitivo en precio. Semanas antes había lanzado Kimi Code, un agente de IA de programación que a su vez compite con Gemini Cli

Image: Xataka
Hace unos días, la empresa china Moonshot AI lanzaba Kimi K2.6, su nuevo LLM que compite con las familias de modelos de Gemini, GPT y Claude y que además es especialmente competitivo en precio. Semanas antes había lanzado Kimi Code, un agente de IA de programación que a su vez compite con Gemini Cli, Codex y Claude Code. La pregunta es obvia: ¿puede realmente competir el binomio Kimi Code/Kimi K2.6 con el binomio de moda, Claude Code/Opus 4.7? La respuesta es complicada.
Un modelo estupendo (pero no perfecto). Kimi K2.6 es un modelo de pesos abiertos con un billón de parámetros en total (un trillón americano), de los cuales están activos 32.000 millones de parámetros y que usa la ya conocida arquitectura de Mixture-of-Experts. En el artículo de lanzamiento se muestra su rendimiento comparado con el de GPT-5.4 y Opus 4.6 y lo cierto es que sus números en estas pruebas sintéticas parecen realmente excelentes:
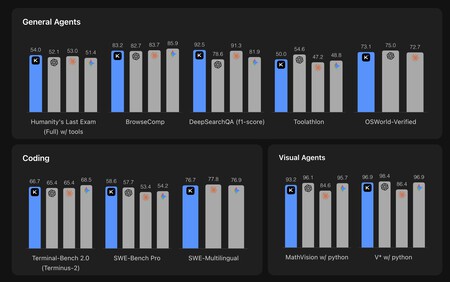 Aquí Kimi K2.6 está comparado con GPT-5.4, Claude Opus 4.6 y Gemini 3.1 Pro. Fuente: Moonshot AI.
Aquí Kimi K2.6 está comparado con GPT-5.4, Claude Opus 4.6 y Gemini 3.1 Pro. Fuente: Moonshot AI.
Hasta 8 veces más barato que Opus 4.6. Tiene planes de suscripción estilo Claude Pro o ChatGPT Plus, pero además se puede usar vía API. El precio en ese caso es de 0,60 dólares por millón de tokens de entrada (0,16 si están en caché) y 4 dólares por millón de tokens de salida. Claude Opus 4.6 cuesta 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida, es decir, hasta ocho veces más. Claude Opus 4.7 tiene el mismo precio y teóricamente es mejor en rendimiento, pero cuando se anunció Kimi K2.6 esta versión aún no había aparecido (ni tampoco GPT-5.5).
La magia del enjambre de agentes de IA. Claude Code trabaja de forma secuencial. Analiza el problema, ejecuta un paso, comprueba el resultado y decide cómo sigue actuando. En Kimi Code se usa un enfoque diferente: un "agente maestro" divide o descompone la tarea que le pedimos en subtareas independientes y a partir de esa división lanza hasta 300 "subagentes" que corren en paralelo y son capaces de coordinar hasta 4.000 pasos de forma simultánea.
¿Muchos trabajando a la vez mejor que uno solo? Es el llamado "enjambre de agentes" de Kimi K2.6 que se aprovecha al máximo en Kimi Code y que también podemos activar en su versión gratuita en su web oficial. En Kimi K2.5 se podían lanzar hasta 100 subagentes y 1.500 pasos, así que el salto es significativo. En pruebas internas Moonshot mostró cómo esos enjambres lograron por ejemplo "refactorizar" un motor financiero de código abierto trabajando 13 horas seguidas y más de 1.000 llamadas a herramientas con una mejora del 185% en el rendimiento medio. Por supuesto, se trató de pruebas internas.
Artículo original
Kimi Code hace el 75% de lo que hace Claude Code al 20% de su precio. La pregunta es si ese 25% que falta es el que importa
Publicado por Xataka